Cargando...
La innovación, nuestra razón de ser
Cuando hace unos meses escribí sobre las capacidades geográficas de Proxia®, introduje el problema al que se enfrenta cualquier aplicación cuyo objetivo es ser ejecutada en varios nodos del mismo clúster. De hecho, diseñar y elaborar la arquitectura de una aplicación empresarial no sólo va de decidir si vamos a utilizar o no micro-servicios o del uso de un stack tecnológico concreto, sino que debemos enfrentarnos a cuestiones tales como ¿qué hará el sistema ante situaciones de alta carga o stress? La respuesta, bastante obvia, por cierto, pasa por un crecimiento horizontal de los nodos del clúster. Pero ¿son estos nodos realmente independientes? ¿necesitan compartir información? ¿van a recibir y enviar mensajes, o es sólo un problema de caché?
En mi opinión cuando hablamos de servidores en un clúster, estamos hablando de problemas de mensajería. Seguramente podríamos discutir que en un entorno típico de clúster lo que necesitamos es compartir información y estado entre los diferentes nodos que lo componen, así que ¡es un problema de caché! Dejadme que lo analice un poco más en detalle.
En primer lugar, si la aplicación necesita almacenar información en caché lo va a necesitar tanto si es una aplicación mono-nodo como multi-nodo. La caché, a fin de cuentas, se utiliza para optimizar los tiempos de lectura – evitando accesos a la base de datos – o para tener un estado en memoria que podemos necesitar en una fase posterior de nuestro programa, imaginaos una autenticación tipo OAuth. Por tanto, cuando escalamos nuestra aplicación horizontal nuestra caché local necesita expandirse para soportar nuevos problemas pero que no son propiamente de la caché, del almacenamiento, sino de la mensajería.
Además, no podemos ignorar, que en ocasiones lo que nuestro sistema necesita es sólo mensajería. Imaginad por un momento, que vuestra aplicación es una aplicación que hace uso intensivo de websockets para la comunicación con el usuario final. Cuando escalamos la aplicación, ¿cómo resolvemos los problemas de comunicación entre los usuarios finales, cuando la conexión TCP es usuario-servidor, y los usuarios están en distintos servidores? ¿es, realmente un problema de caché, o más bien un problema de mensajería entre los diferentes nodos del clúster?
Si bien hay varias soluciones para resolver este problema en este post me centraré en como hemos dado respuesta a estos problemas en Divisa iT.
Al diseñar un sistema de mensajería hay varios problemas que podrían aparecer en un momento otro. Así, de forma esquemática, ¿están todos los nodos vivos? ¿responden adecuadamente a las peticiones? ¿cómo puedo detectar si un nodo se ha caído o ha vuelto a dar servicio? ¿cómo identificamos a un nodo? ¿ejecutan todos los nodos la misma versión de código? ¿voy a proporcionar alguna solución de resguardo?
Más allá de estos problemas internos del propio sistema de mensajería, tenemos otros problemas externos, principalmente relacionados con la extensibilidad del sistema, o mejor dicho, con facilitar la adopción del sistema por parte de los desarrolladores.
Cuando diseñamos nuestra solución, no solo queríamos que fuera autogestionada, sino que además buscábamos la forma de interactuar con ella desde una consola de gestión externa, a ser posible centralizada y que pudiera servir no sólo para nuestro caso de uso sino para otros que tuviéramos bien internamente o bien nuestros clientes. Ello nos obligó a pensar en sistemas estándar – o estándares en aquellos días – así que decidimos utilizar JMX, lo cual nos facilitaba tanto la gestión desde JConsole como desde un panel de control SNMP.
La utilización de la pila JMX nos resolvió alguno de los problemas identificados con anterioridad, tales como la identificación del nodo, pero muchos de ellos están fuera del propio ámbito de JMX, así que tuvimos que tomar decisiones,
No obstante, hay otros muchos problemas a resolver. La solución, utilizar una máquina de estados como la mostrada en la siguiente imagen.

Utilizar esta máquina de estados nos permite saber:
Generalmente, cuando queramos mejorar la adopción del cualquier sistema necesitamos enfocarnos en lo que los usuarios hacen y cómo lo hacen. Dando soluciones tanto generales como particulares en aquellos casos que se implementen siempre de la misma forma y tengan un alto grado de repetición.
En nuestro caso y teniendo en cuenta a lo que nos enfrentábamos optamos por una solución dual. Por una parte, un subsistema orientado a solventar problemas de mensajería y, por otra parte, otro subsistema limitado al uso de la cache. Éste último utilizaría el mismo sistema de mensajería, pero con una capa definida y un tanto dogmáticas sobre éste.
En cualquier caso, ambos sistemas se apoyan en las características de Java y su soporte de anotaciones, puedes ver mi post anterior si estas interesado en saber algo más de como las usamos en Divisa iT.
El uso del subsistema de caché es bastante directo desde el punto de vista del desarrollador, puesto que sólo es necesario anotar nuestra clase.

Aunque claro la magia se implementa por debajo, con la ayuda de algo de ASM

No voy a entrar en mayores detalles, puesto que hablaré en mayor profundidad de nuestro sistema de caché en un post futuro.
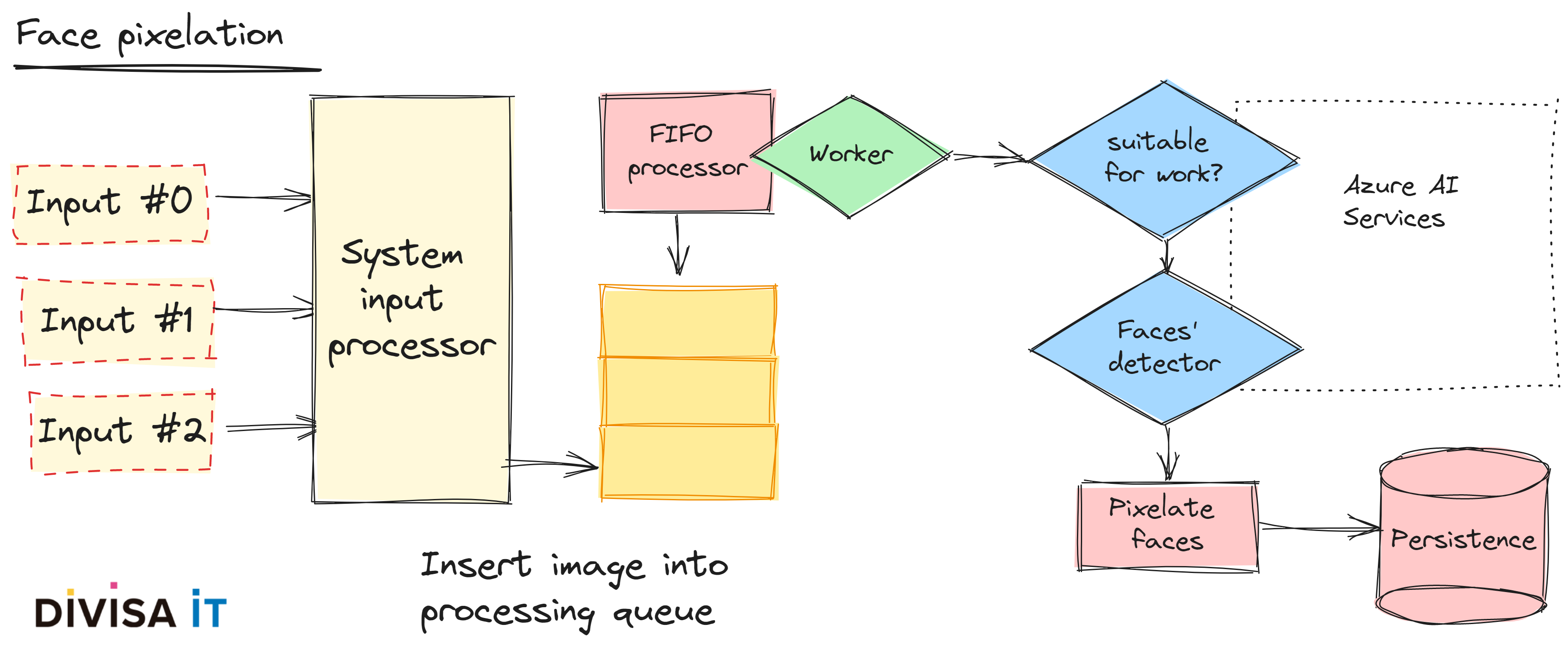
Se trata, es innegable, de un sistema más complejo de utilizar en el que diferenciamos entre la implementación del servidor que se realiza como muestra la siguiente figura.

Y la implementación de cliente, que es un poco más complicado de utilizar puesto que, hasta la fecha, no estamos creando ningún esqueleto que simplifique su empleo.

A decir verdad, utilizamos esto para tareas más complejas que no son habituales en el día a día, como, por ejemplo,
Aunque obvio, el proceso de desarrollo de esta solución no ha sido directo. Hemos seguido un proceso iterativo a lo largo de los años, aprendiendo de los errores, reemplazando grandes fragmentos de código, aunque manteniendo el interfaz hacia el exterior, añadiendo un sistema de testing decente, permitiendo el crecimiento hacia distintos casos de uso, etc.
Si te interesa lo que hacemos y cómo lo hacemos no dudes en aplicar a nuestras ofertas de empleo.
 David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales
David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales